










1 мин чтения
Livepage — лидер премии Clutch Global Fall 2024

Узнайте из статьи, чем опасны повторяющиеся страницы на сайте, какие они бывают, а также как найти дубли страниц. Мы расскажем про способы устранения полностью или частично похожих страниц, чтобы вы могли обезопасить свой ресурс от негативных последствий.
Статья будет полезна практикующим SEO-специалистам и владельцам сайтов.
Дубликат — полное или частичное повторение контента на двух или более страницах сайта. Повторы плохо воспринимаются поисковиками и ведут к ухудшению ранжирования, а иногда и к попаданию под фильтры.
Основные проблемы, возникающие при наличии дубликатов:
1. Ухудшение индексации сайта. Наличие «двойников» увеличивает количество страниц сайта, которые нужно обойти поисковому роботу. Это плохо как для огромного проекта с несколькими тысячами страниц, так и для небольшого ресурса. Ведь робот за обход не сможет охватить все страницы и проиндексировать их. Помимо того, в индекс могут попасть сначала страницы-дубликаты, продвижение которых не планировалось, в то время нужные останутся без внимания и индексация исходных версий страниц затянется.
2. Ухудшение ранжирования всего ресурса в поисковой системе из-за неуникальности контента.
3. Неправильное распределение внутреннего ссылочного веса. Страница-дубликат может получить больший ссылочный вес, чем страница-оригинал за счет ошибок в перелинковке. В итоге значимой становится вовсе не та страница.
4. Изменение релевантной страницы в поиске. Поисковый алгоритм на основе пользовательского поведения может посчитать дубль релевантнее запросу и сменить страницу в выдаче. А это может приводить к снижению позиций.
5. Неправильное распределение внешнего ссылочного веса. Когда пользователь захочет поделиться с кем-то ссылкой на определенную страницу, то высока вероятность, что он будет ссылаться именно на дубликат. Это грозит тем, что ссылочный вес достанется странице-дублю.
Google серьезно относится к проблеме повторяющихся страниц, особенно при их большом количестве.
Предполагается, что дублирование может возникать при манипуляции рейтингом в поисковой системе: для увеличения трафика обманным путем или введения пользователя в заблуждение.
Одинаковые страницы появляются и без злого умысла у интернет-магазинов, форумов, при разных версиях сайта (для мобильных устройств, для печати).
Алгоритм поисковика настроен таким образом, чтобы индексировать и выводить в выдачу страницы с уникальным контентом. И если робот посчитает контент дубликатом — пересматривается рейтинг ресурса в сторону снижения, вплоть до полного отсутствия в выдаче.
Чтобы начать поиск и устранение дублей, важно определиться с их типом, поскольку процесс очистки будет отличаться. Итак, все дубликаты на сайте делят на две большие группы:
— будет полностью идентичный контент. Страница одна, отличаются только URL.
Дополнительно выделяют:
— когда полностью повторяется тег
;
Полные дубли:
| Тип полных дублей | Пример |
|---|---|
| Страницы, доступные по адресам с www и без www в URL | https://www.site.com https://site.com |
| Со слешем и без слеша в конце в URL | https://www.site.com/ https://site.com |
| Два и больше слеша в середине URL | https://www.site.com/catalog///uslugi https://site.com/catalog///////uslugi |
| C html, php и без в конце URL | https://site.com/index.html https://site.com/index.php |
| С http и https в начале URL | https://site.com http://site.com |
| Разный регистр букв в URL | https://www.site.com/catalog https://www.site.com/CATALOG |
| С Get параметрами в URL (?, ?utm= или другие) | Страница https://site.com/index.php?example=10&product=25 полностью соответствует https://site.com/index.php?example=25&cat=10 |
| Дубли, связанные с ошибками при создании или изменении структуры, когда один и тот же товар доступен по разным URL | https://site.com/catalog/dir/product https://site.com/product https://site.com/dir/product https://site.com/catalog/tovar |
| Не переведенные языковые версии или неправильная их реализация | https://site.com/catalog/product https://site.com/en/catalog/product |
| Сайты зеркала | По разным URL находится идентичная информация. При этом сайт дубликат открыт для индексации |
Причины полных дублей:
. Если не указать поисковикам на изменения, они будут видеть один и тот же контент по двум протоколам.
и
.
Частичные дубликаты
| Тип частичных дублей | Суть | Пример |
|---|---|---|
| Страницы пагинации, фильтров, сортировок | Изменение порядка выводимого ассортимента продукции в каталоге может поменять URL с сохранением всей информации, заголовков и мета-тегов | https://site.com/catalog/category/ – изначальный адрес страницы категории
https://site.com/catalog/category/?page=1 – страница пагинации |
| Страницы отзывов, комментариев, характеристик | Случается, что при выборе вкладки на странице продукта в URL добавляется параметр, однако контент остается прежним | https://site.com/catalog/shapka – основная страница карточки товара
https://site.com/catalog/shapka?razmer=1 – карточка товара с размером. Цена и характеристики при этом не меняются. |
| Версии для печати, PDF для скачивания | Такие страницы полностью повторяют контент при упрощенной версии вывода информации для печати или сохранения в другом формате | https://site.com/catalog/ – каталог
https://site.com/catalog/print – черно-белая версия для печати https://site.com/catalog/print?color=1 – цветная версия для печати |
| HTML-слепки страниц сайта, созданные через AJAX | Найти дубли страниц на сайте можно, заменив в URL страницы «
!# » на « ?_escaped_fragment_= ». В индекс страницы-двойники попадают только в том случае, если допущены ошибки при индексации AJAX страниц с последующим перенаправлением робота на страницу-слепок. И тогда робот обрабатывает два URL: основной и его HTML-версию. |
https://site.com/#/page/
https://site.com/?_escaped_fragment_=/page/ |
Причины частичных дублей:
Копии
негативно сказываются на продвижении ресурса. Это связано с особенностями и функциями тега: текст из главного заголовка отображается в выдаче в виде ссылки на страницу. Если у вас окажутся повторы, то поисковый робот выберет только одну из дублирующихся страниц, даже если контент будет отличаться.
Важно!
Если 2 разных товара названы одинаково, стоит уникализировать название или включить в
артикул.
Для некоторых движков есть типичные дубли. Например:
1. Битрикс при формировании URL для каталога выдает дубликаты детальных страниц при отсутствии привязки к нескольким разделам:
2. WordPress создает копии несуществующих документов:
3. Joomla формирует два URL — «человеческий» и системный, из-за чего появляются копии страниц:
Обычно такие дубликаты устраняются через SEO-плагины и с помощью правильной структуры сайта.
Суть этого вида дубликатов: тексты могут быть технически уникальными, но схожими по смыслу. То есть одна и та же информация подается разными словами. Самыми распространенными типами являются:
Этот тип относится не к техническим дубликатам, когда повторы возникают из-за неправильных настроек, а к дубликатам, созданным человеком по невнимательности.
Дубли по регионам возникают, когда вы предлагаете товары или услуги в разные города и страны, но при этом используете одинаковый контент.
Если вы ориентированы на один регион, переживать о наличие таких дублей не нужно. Однако при работе с разными странами поиск дублей страниц сайта обязателен.
Ситуация возникает при описании одинаковых услуг и товаров с помощью синонимов, например:
Мы говорим про одно и то же только разными словами, а смысл не меняется — по сути это рерайтинг в рамках одного сайта. При этом URL, Title, Description, заголовок будут отличаться.
Такого повторения контента следует избегать, поскольку поисковики накладывают санкции на сайты с синонимическими дублями. Так, они называют такие страницы низкокачественными, а в итоге может ухудшиться ранжирование и позиции всего ресурса понизятся.
Бывает, что текст полностью или частично повторяется на разных страницах. Причина — умышленное или неосознанное копирование контента.
Такие страницы поисковый робот приравняет. При этом их релевантность время от времени изменяется, а порой страницы и вовсе не попадают в индекс.
Принцип поисковых систем: одна страница = один URL = уникальная информация на странице.
Поэтому чтобы уберечься от потери трафика и позиций в выдаче, продвигать и развивать ресурс, важно найти и удалить все дубли.
В поиске помогут:
Страницы, повторяющиеся полностью или фрагментами, найти на сайте легко с помощью такой комбинации:
site: имя сайта пробел фрагмент текста.
В выдаче появятся все страницы с искомой фразой на сайте:
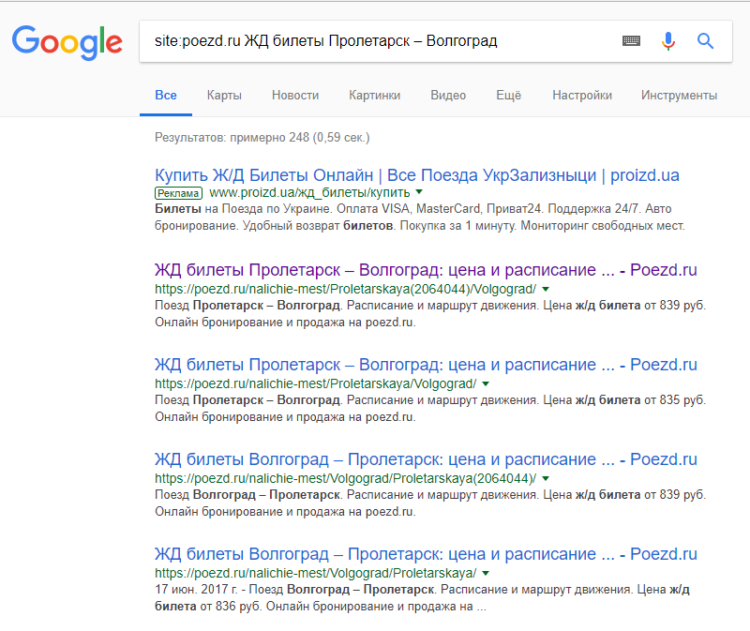
Мониторинг выдачи через «site:» на примере сайта poezd.ru. Перечень полных дублей по фразе «ЖД билеты Пролетарск — Волгоград»
Понять, есть ли полные дубли поможет информация в сниппете: если вы увидели фразу, введенную в строку поиска, жирным шрифтом на 2 и более страницах, то это говорит о наличии дубликатов.
Важно!
Вводимый текст через «site:» не должен быть больше 1 предложения. А искать стоит без точки.
Чтобы проверить дубли страниц на сайте с одинаковыми мета-описаниями, в консоли Google Search Console перейдите на вкладку «Оптимизация Html». В результате вы получите список потенциальных копий.
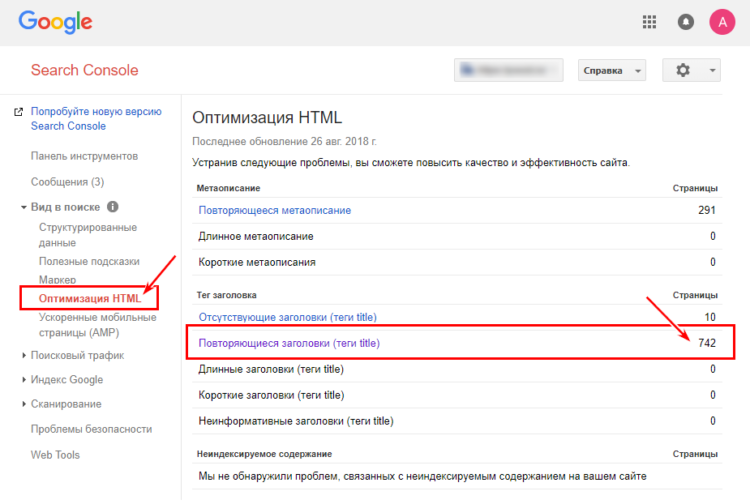
Поиск дубликатов в Google Search Console
Команда Livepage рекомендует программы:
Программа используется для мелких и средних проектов. Эффективно сканирует на наличие полных и фрагментированных дублей страниц, названий, мета-данных, заголовков.
Кроме того, с Seo Spider вы сможете проанализировать правильность составления мета-тегов, найти неработающие ссылки, провести аудит и другое.
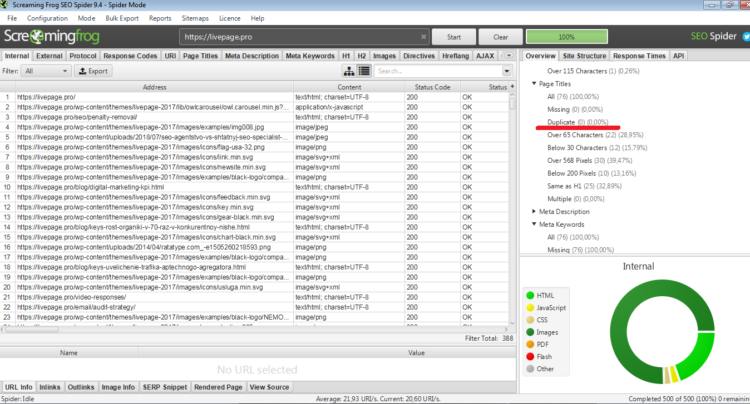
Итог после проверки отображен справа, в каждом пункте раскрываются несколько проблем и их количество
Программа поможет провести полный аудит сайта и выявить проблемы, неточности и ошибки. Всего Netpeak определяет 62 ошибки в 54 параметрах, среди них:
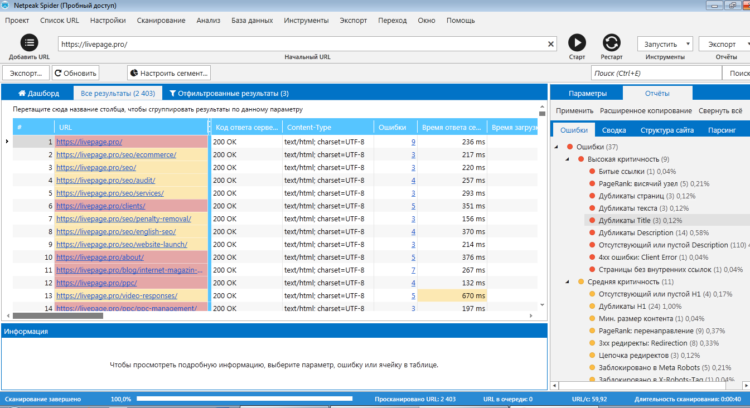
Отчет проверки в Netpeak. Слева отображаются ошибки, узнать подробности можно, кликнув на параметр или ошибку
С Xenu Link Sleuth также просто проверить сайт на наличие дублей страниц. Программа выполняет технический аудит сайта и находит полные копии, в том числе и заголовков. Однако частичные дубликаты она не видит.
После установки в строку ввода прописываете адрес сайта, сканируете, сортируете результаты, сравниваете совпадения.
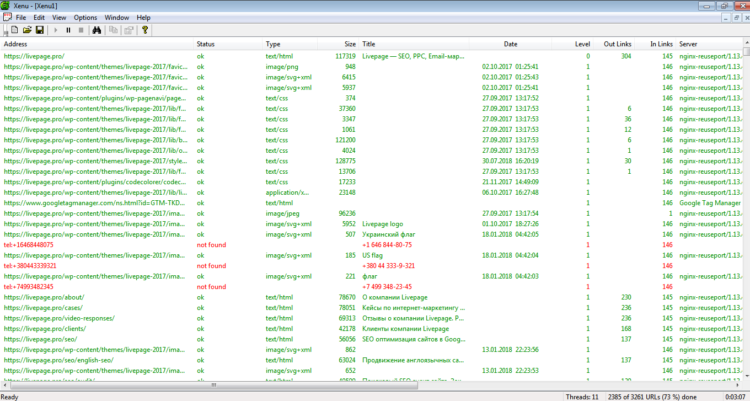
Результаты проверки в Xenu Link Sleuth
Самыми популярными и эффективными являются такие сервисы:
* Цены актуальны на август 2018 года
** Помните, что результаты проверки не являются истиной последней инстанции. Выявленные проблемы — это не 100% проблемы, это лишь показатель того, на что важно обратить внимание, перепроверить и при необходимости исправить!
Платформа проводит технический SEO-аудит сайта, анализируя больше 50 ошибок. Среди всех возможных проблем и потенциально опасных ситуаций сервис выявляет дублированный контент на сайте на двух и больше страницах. Сервис видит:
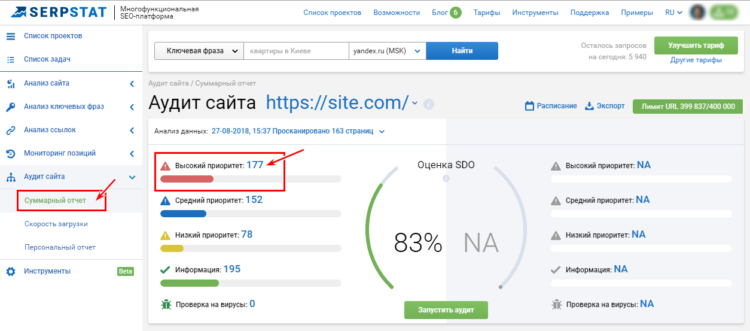
Общий результат проверки в сервисе Serpstat
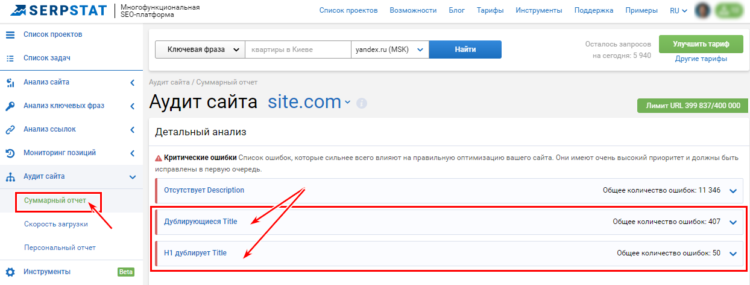
Подробный отчет результатов проверки в Serpstat
Сервис предоставляет бесплатный функционал и платные планы индивидуального использования от $19 и для компаний от $499 в месяц.
Сервис, позволяющий мониторить ошибки на сайте:
Регистрируетесь, добавляете проект и запускаете сканирование. Результат предоставляется в виде таблицы:
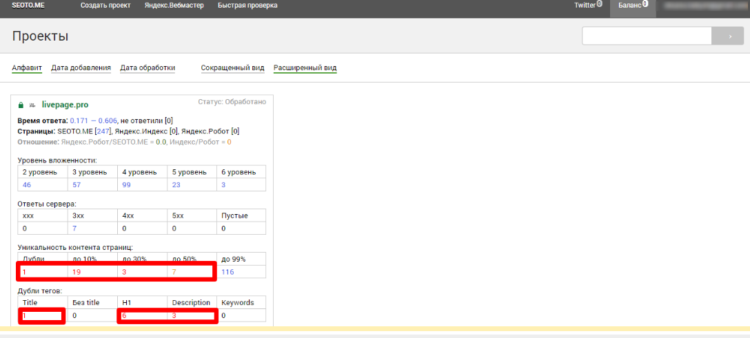
Общий результат проверки в Seoto.me
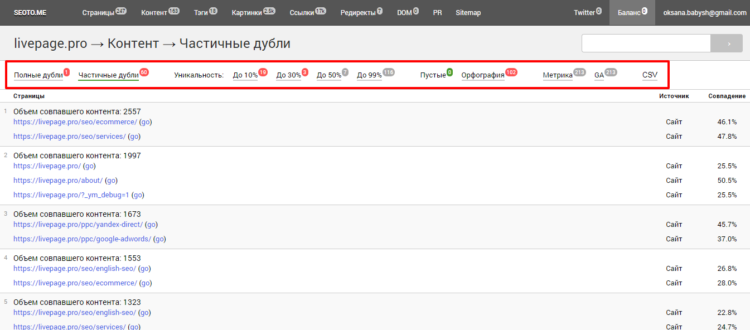
Детализация результатов по всем параметрам
Сервис работает бесплатно для 3-х проектов. Далее плата за проект — 500 рублей.
Онлайн-сервис поможет не только проверить сайт на дубли страниц, но и такие ошибки:
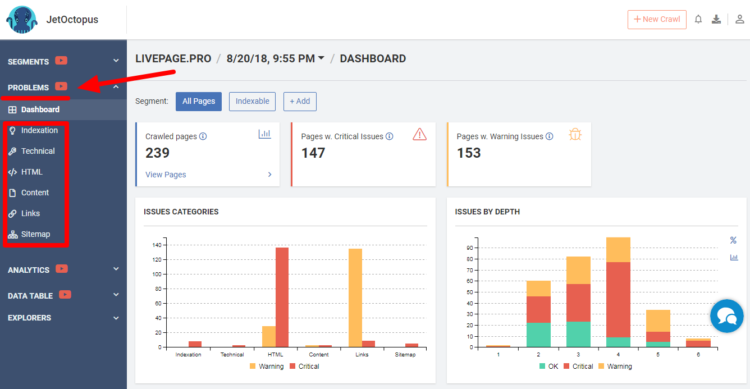
Отчет проверки сайта JetOctopus. Детально увидеть возможные проблемы можно, перейдя на соответствующие вкладки слева
JetOctopus предлагает пробную версию бесплатно, потом можно выбрать подходящий тарифный план — от 20 € в месяц.
Важно! Преимущество сервиса — он может определять смысловые дубликаты. То есть страницы похожие по контенту, но уникально написанные.
Этот способ актуален для маленького ресурса. Заключается в ручном подборе возможных вариаций URL, в которых могут быть дубли (примеры описывали выше).
Однако метод требует больших затрат времени, к тому же легко что-то пропустить или забыть.
Кроме того, вручную ищут и смысловые дубликаты, а именно синонимические. Важно аналитически подходить к такому редакторскому аудиту сайта: проверяйте статьи на схожесть информации, повторы фраз и абзацев другими словами. Задавайте вопрос, про что статья, и если будут совпадения — удаляйте одну из них.
Перед удалением дублей важно разобраться в причине их возникновения и устранить ее.
При этом в каждой ситуации необходимо индивидуально подбирать решение об их удалении или оставлении. Однако помните, если дубликаты функционально не оправданы, от них лучше отказаться.
Итак, убрать дубли можно с помощью:
;
;
и
;
Смысловые дубли можно нейтрализовать несколькими способами:
Тег
используется для страниц, которые должны продолжить существовать.
Цель применения — закрыть поисковому роботу доступ к странице. При этом можно:
;
.
Размещать тег нужно в HTML-коде дублирующихся страниц между тег
.
301 редирект — способ перенаправления пользователей с одной страницы на другую, при использовании которого они «склеиваются». При этом ссылочный вес передается со старой страницы на новую.
Настройка 301 редиректов используется, когда нужно убрать дубли страниц на сайте, которые не должны существовать.
Внедрить этот способ борьбы с дублями можно либо через файл .htaccess в корневой папке сайта. Примеры синтаксиса кода вы можете посмотреть в статье.
Важно!
Если у вас нет опыта в программировании, а в штате нет программиста, воспользуйтесь технической поддержкой хостинг-провайдера. Или же установите плагины для настройки редиректов, например, Safe Redirect Manager, Redirection, Simple 301 Redirects. А, например, CMS Joomla или Wix имеют встроенные инструменты редиректа.
Установка тега
— работающий вариант для страниц:
Этот способ актуален, если не получается удалить страницы-дубли. Тогда важно указать главную (каноническую) страницу, более предпочтительную для индексации, чтобы боты обращали внимание только на нее.
В HTML-код текущей страницы между тегами…помещаем атрибут
.
В HTML-коде это выглядит так:
.
и
С помощью
и
связываются отдельные страницы в цепочки. Стоит учитывать, что метод действенен только для страниц пагинации и только для Google. Однако этот тег лишь вспомогательный атрибут, и как правило, не является обязательная директива.
Кроме того, важно отслеживать правильность генерации тегов и отслеживать четкую последовательность между страницами пагинации. Это поможет избежать бесконечных цепочек.
Размещают атрибут на первой странице в разделе
:
Для всех последующих страниц добавляем атрибут
и
, которые будут указывать на предыдущий и следующий URL.
Учитывая, что это первая страница, добавлять нужно только
. Например, на второй странице
нужно добавить ссылки:
На завершающей странице
, как и на первой, необходимо указать только один атрибут. Важно, в данном случае он указывает на предыдущий URL:
Закрыть доступ к разделам и страницам можно с помощью файла robots.txt. Однако это не гарантирует избавление от дублей. Поскольку некоторые страницы могли попасть в индекс, и после добавления запрета они остаются доступными для поисковых систем. То есть вы сможете противостоять новым дублям, но через robots.txt не получится удалить старые.
Способ применяется, когда не подходит никакой другой вариант. Подходит для закрытия служебных страниц, частично повторяющих контент основных.
В файле robots.txt прописываете страницы, которые хотите скрыть, а перед ними ставите слеш.
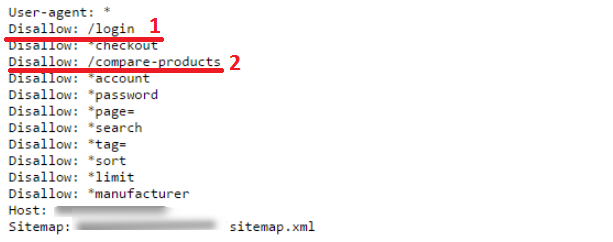
Визуально настройка robots.txt выглядит так: 1 – закрыта страница входа в личный кабинет, 2 – закрыта страница сравнения товаров
Этот способ поможет в решении проблемы региональных дублей.
Чтобы у поисковиков не было вопросов к вашему ресурсу, продвигайте регионы на разных поддоменах. Для каждой страны лучше иметь национальный домен. Это облегчит продвижение и не повлечет за собой санкций от поисковых систем.
Читайте подробнее о пагинации на сайте.
и
Представленные теги используются, когда:
Они предотвращают склеивание страниц при повторяющемся контенте.
Визуально пример нейтрализации дублей выглядит так:
Применяя описанные методы, найти дубликаты страниц на сайте и избавиться от них для оптимизации ресурса будет проще.
Остались вопросы по вашему сайту? Напишите нам и мы поможем найти все дубликаты и оптимизировать ваш проект.


«Команда Livepage доказала, что является надежным источником для быстрого роста в Интернете. Мы начали с 2 000 посетителей в месяц. За 3 года вместе с Livepage мы достигли 70 000 посетителей и более 100 лидов с сайта в месяц.»


«Мне приятно знать, что мы можем быть на связи в любое время. По поводу результатов: да, с 2015 года мы работаем, по сути 6 лет, и наш трафик в самые яркие моменты вырос в 5 раз. Я не могу сказать, что Livepage была нашей первой SEO компанией, но стала первой удачной SEO компанией.»

«SEO работает! Если кропотливо и методично заниматься оптимизацией контента, то это приносит плоды. Мы установили этот факт благодаря работе с Livepage. Хочется отметить, что компания использует широкий набор инструментов, подходов, все совместные проекты были хорошо распланированы, при необходимости ребята мгновенно подключают дополнительных специалистов.»


«Я доволен быстрым выполнением заданий и мгновенными ответами на мои сообщения.»


«Мне нравится комплексный подход, который предлагает команда Livepage. Абсолютно все члены команды работают вместе; все в курсе деталей проекта. У нас одна общая цель – увеличить продажи наших услуг, и команда прилагает максимум усилий для достижения цели.»


«Специалисты Livepage — это опытные и клиентоориентированные профессионалы, с которыми легко работать. Мы были приятно удивлены тем, как быстро команда Livepage разобралась в особенностях нашего бизнеса и развернула PPC кампании с учетом наших бизнес-целей. Это помогло нам увеличить прибыль и ROI в кратчайшие сроки.»
